 09.03.2019, 20:59
09.03.2019, 20:59
|
#1 |
|
Модератор
Регистрация: 16.01.2015
Сообщений: 1,609
|
По просьбе некоторых форумчан и просто осознавая полезность этой информации, выкладываю инструкцию по созданию самопрограммирующего аудиофайла с наложением розового шума, или попросту в народе, «шипелки»
 Постараюсь сделать инструкцию подробной и надеюсь, что будет понятно людям с любым уровнем компьютерной грамотности. Если кто не в курсе, таким образом можно записывать какие-то тексты/формулировки и, используя специальный алгоритм, превращать их в эффективный инструмент для более глубокого донесения до подсознания информации о желаемых изменениях. Постараюсь сделать инструкцию подробной и надеюсь, что будет понятно людям с любым уровнем компьютерной грамотности. Если кто не в курсе, таким образом можно записывать какие-то тексты/формулировки и, используя специальный алгоритм, превращать их в эффективный инструмент для более глубокого донесения до подсознания информации о желаемых изменениях. В одной из семинарских веток выложен подобный алгоритм, но выяснилось, что он там не совсем корректно описан и сделан. Основным отличием является то, что там предлагается дорожки с голосом делать тише, а розовый шум громче, но при этом голос оставлять, и он слышен при проигрывании. Однако, мы склонны считать, что техника работает лучше, если голос модулирован розовым шумом и не слышен на осознанном уровне вообще. По такому принципу, в частности, работают диски Патрушева. Итак, для начала нужно скачать программу Adobe Audition версии 1.5 (именно эта древняя версия, в другой не получится сделать то, что мы хотим). 1. Чтобы записать аудио, либо нажимаем на красную кнопочку записи в левом нижнем углу, либо выбираем в меню File – New (на картинки можно кликнуть, и они откроются в лучшем качестве):  После этого программа предложит выбрать параметры, выбираем такие:  2. После того как записали аудиофайл, идём в меню Effects – Amplitude – Normalize, нажимаете «ОК». 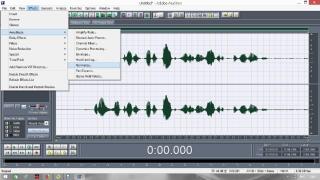 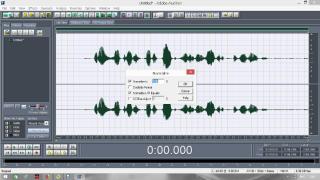 3. Далее нажимаем кнопку, которая выделяет одну дорожку, например, нижнюю:  4. Идём в меню Effects – Reverse, чтобы развернуть одну из дорожек в обратную сторону: 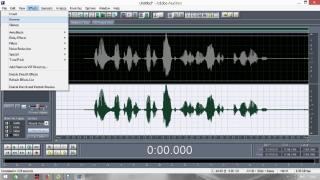 5. Нажимаем на кнопку с двумя дорожками: 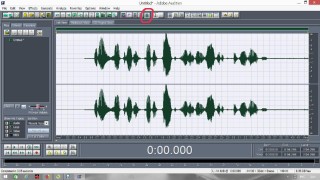 6. Теперь будем сжимать и растягивать этот файл по времени. Нажимаем Ctrl C, чтобы скопировать получившееся. Далее идём в меню File – New (как в самом начале, см. пункт 1, только не нажимаем на красную кнопочку, а именно через меню, потому что нам не нужно записывать ничего нового; программа опять предложит выбрать параметры, они должны были сохраниться, можно сверить на всякий случай, нажимаем «ОК»). Нажимаем Ctrl V, то есть вставляем скопированный файл. Идём в меню Effects – Time/Pitch – Stretch: 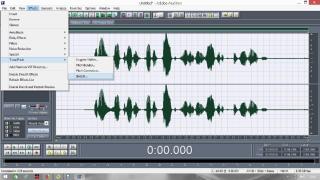 Пишем «137»: 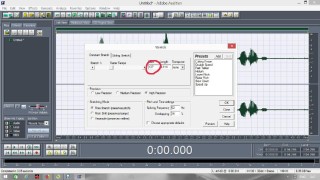 7. Далее опять создаём новый файл и делаем всё то же самое (см. пункт 6), только пишем число 237. 8. Повторяем то же самое, но пишем число 73. 9. Повторяем и пишем число 42. 10. У нас получилось 5 файлов: 1 исходный, 2 ускоренных и 2 замедленных. Теперь мы нажимаем кнопочку Multitrack View: 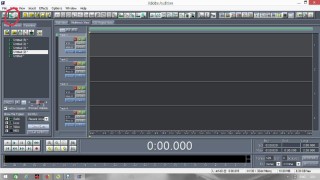 11. Там мы выстраиваем стык в стык получившиеся файлы в одной из дорожек (просто перетаскиваем их мышью) и выделяем их все (нажимаем на один, затем удерживая кнопку Ctrl, нажимаем на все остальные). Я записала файл, который длится несколько секунд, поэтому файлы такие коротенькие и маленькие. У вас получатся длиннее: 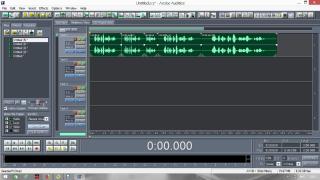 12. Кликаем на один из них правой кнопкой мыши и выбираем Mixdown to file (программа предложит сохранить что-то, можно нажать No): 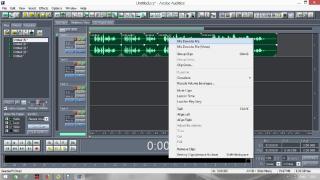 13. Далее опять нажимаем кнопочку Multitrack View (см. пункт 10). Удаляем файлы из дорожки, кликнув по ним правой кнопкой мышки и выбрав Remove Clips. Перетаскиваем туда свежесозданный файл Mixdown. 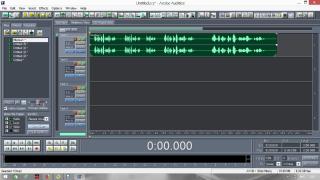 Переходим обратно в режим, в котором отображается всё по одному файлу. Для этого либо дважды кликаем по его названию, либо нажимаем на кнопочку, как на фото ниже. Смотрим в правом нижнем углу, какой он получился длительности (у меня получился 25 секунд, в любом случае переводим всё в секунды).  14. Теперь будем генерировать розовый шум. Опять создаём новый файл (см. пункт 1). В меню выбираем Generate – Noise: 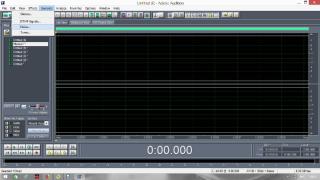 15. В открывшемся окошке параметры должны выглядеть следующим образом (а внизу вставляем количество секунд (именно секунд!) получившегося файла, в моём случае 25): 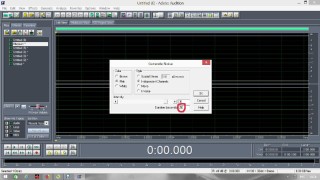 16. Нажимаем ОК и по мере генерации розового шума модулируем его сознанием, то есть мысленно прописываем то, что вы написали в тексте, который записали голосом, только в образной форме. То есть представляете картинку желаемого конечного результата по сути. В зависимости от длины файла будет разная скорость генерации шума (от нескольких секунд до нескольких минут). 17. Опять идём в режим Multitrack View (см. пункт 10). Перетаскиваем свежесозданный файл с розовым шумом (у меня он называется Untitled (6) ) на вторую дорожку под файл Mixdown. Выделяем их вместе (нажимаем на один, нажимаем и удерживаем Ctrl, нажимаем на второй). Теперь нажимаем Shift, держим его и одновременно нажимаем стрелочку вправо до тех пор, пока не достигнете конца файлов (если что, можно вернуться и откорректировать, нажимая на левую стрелочку, удерживая Shift): 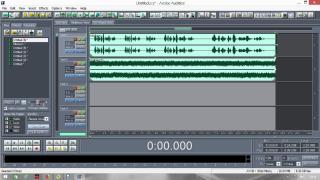 18. Нажимаем Ctrl A (не пропустите этот момент, это очень важно!). 19. В меню выбираем Effects – Vocoder: 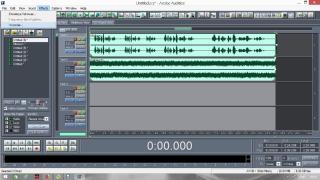 20. Проверяем, что в графе Control Wave (voice) стоит Mixdown, а в Process Wave (synth) – файл с розовым шумом, у меня он Untitled (6): 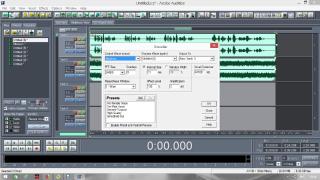 21. Нажимаем «ОК», ждём, когда файл сгенерируется (время зависит от длины файла, может занимать от, например, 20 минут до часа и более). Не советую записывать изначальный текст дольше 5-7 минут, иначе получится гигантский файл. 22. Сгенерированный файл у меня появился под названием New Track 3, в любом случае, он будет в самом верху. Кликаем на него дважды. Проверяем, что он записался правильно — голоса не должно быть слышно, только шипение. Для этого нажимаем на кнопочку play в левом нижнем углу. Если голос слышно, то нужно всё переделать. Если всё в порядке, то сохраняем файл. 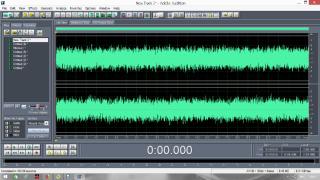 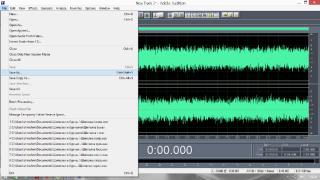 23. Затем перетаскиваем его на телефон (или где вы будете его прослушивать). Возможно, понадобится карта памяти, потому что файл может оказаться очень тяжёлым (иногда около гигабайта). Зависит от вашего телефона и остатка памяти на нём. Также обратите внимание, что при копировании файла на телефон вас будут спрашивать, хотите вы преобразовать файл или только скопировать. Нажимаем «только скопировать»! Это тоже важно. Файл должен быть в формате wav, и обычно он проигрывается на телефонах (по крайне мере, на андроидах) с помощью VLC плеера, который можно скачать на Play market. Также можно записать исходный файл на любой диктофон, но для работы с ним в программе нужно будет конвертировать его в формат wav. В сети есть онлайн конверторы, можно просто набрать в поиске "конвертировать в wav" или что-то такое). Но лучше и удобнее, конечно, записать сразу на ноут в Adobe Audition. По-хорошему нужно иногда менять наушники местами (там одна дорожка файла идёт в обратную сторону, и нужно чтобы эта инвертированная часть файла транслировалась то в правое, то в левое ухо). Но по себе знаю, что это может быть неудобно в плане наушников, поэтому лучше сделать инверсный общий файл и слушать по очереди то один, то другой. Для этого можно просто применить Effects - Reverse к Mixdown до модуляции его розовым шумом и сохранить его с другим названием. Отдельно нужно сказать, что текст для аудиофайла нужно, конечно, составлять аккуратно и грамотно. Можно, как вариант, любой текст начинать со слов "Все следующие формулировки выполняются наиболее эффективным и гармоничным образом для меня (или "для моего физического и психического здоровья")", чтобы исключить какие-то косяки. Также стоит следить за тем, чтобы в тексте не было отрицательных частиц ("не"). Также стоит сказать, что если вы слушаете на телефоне ночью (это самое оптимальное), то лучше телефон переводить на ночь в авиарежим, чтобы не спать с телефоном у головы и тела с фонящими сотовым и вайфай сигналами (вообще, на мой взгляд, вайфай на ночь лучше отключать, ну или не спать рядом с роутером). Также стоит использовать удобные наушники, которые не будут выпадать из ушей во время сна, но при этом будут комфортны и не будут давить на уши. Последний раз редактировалось Черная Пантера; 20.11.2020 в 14:19. |

|

|





 Древовидный вид
Древовидный вид